Biography
I am a postdoctoral researcher at the University of Alberta in Csaba Szepesvári’s lab. My Ph.D. was supervised by Dr. Tadashi Kozuno and Prof. Yutaka Matsuo. I earned my master’s degree at the Nara Institute of Science and Technology under the supervision of Prof. Takamitsu Matsubara.
Download my resumé.
Interests
- Safe Reinforcement Learning Theory
- Bandit Algorithms
Education
-
Postdoctoral Researcher, 2025(Sep)-
The University of Alberta
-
Postdoctoral Researcher, 2025-2025(Sep)
The University of Tokyo
-
Ph.D. in Engineering, 2022-2025
The University of Tokyo
-
M.S. of Science and Technology, 2020-2022
Nara Institute of Science and Technology
-
Exchange Student, 2018
University of California Davis
-
B.E. in Science and Technology, 2016-2020
Keio University
Selected Publications
(2026).
Emergence of exploration in policy gradient reinforcement learning via retrying.
International Conference on Machine Learning (ICML).
(2026).
Revisiting Subgradient Dominance in Robust MDPs: Counterexamples, Hardness, and Sufficient Conditions.
arXiv preprint arXiv:2604.21177.
(2025).
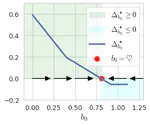
Near-Optimal Policy Identification in Robust Constrained Markov Decision Processes via Epigraph Form.
International Conference on Learning Representation (ICLR).
(2025).
A Unified MDP Framework for Solving Robust, Convex, Multi-Discount Constraints, and Beyond.
Finding the Frame Workshop at RLC 2025.
(2025).
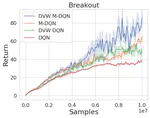
Provably Efficient RL under Episode-Wise Safety in Constrained MDPs with Linear Function Approximation.
Neural Information Processing Systems (NeuralIPS) Spotlight.
(2024).
A Policy Gradient Primal-Dual Algorithm for Constrained MDPs with Uniform PAC Guarantees.
arXiv preprint arXiv:2401.17780.
(2023).
Regularization and Variance-Weighted Regression Achieves Minimax Optimality in Linear MDPs: Theory and Practice.
International Conference on Machine Learning (ICML).
Other Papers
(2023).
(OS 招待講演) 逐次意思決定における諸問題設定と問題に関する事前知識が性能保証に及ぼす影響について.
人工知能学会全国大会論文集 第 37 回 (2023).
(2022).
KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal.
arXiv preprint arXiv:2205.14211.
(2021).
Cautious Actor-Critic.
Asian Conference on Machine Learning (ACML).
(2021).
Cautious Policy Programming: Exploiting KL Regularization in Monotonic Policy Improvement for Reinforcement Learning.
arXiv preprint arXiv:2107.05798.
(2021).
Geometric Value Iteration: Dynamic Error-Aware KL Regularization for Reinforcement Learning.
Asian Conference on Machine Learning (ACML).
(2021).
ShinRL: A Library for Evaluating RL Algorithms from Theoretical and Practical Perspectives.
arXiv preprint arXiv:2112.04123.
Working Experience
Research Part-time
Research Internship
Engineering Internship
Research Internship
Engineering Intern
Projects
*